Unity Catalog with Azure Databricks - First Impressions
This blog post shares my first experience working with Unity Catalog on Azure Databricks. Although it’s been over six months since I completed this proof-of-concept, I wanted to document it before the details faded entirely. While not everything is still fresh in my mind, revisiting the process turned out to be a valuable reflection.
Let's begin with a quick overview of Unity Catalog before diving into the actual proof-of-concept.
- What Is Unity Catalog?
- Proof of Concept
- Considerations for migrating to the TO-BE situation
- Conclusion
What Is Unity Catalog?
Unity Catalog is Databricks’ centralized solution for data governance and cataloging.
As shown in the image below, it acts as a layer between compute and storage, offering:
- 🔐 Fine-grained access control
- 🔍 Data lineage
- 📜 Audit logging
- 📖 Data discovery and cataloging
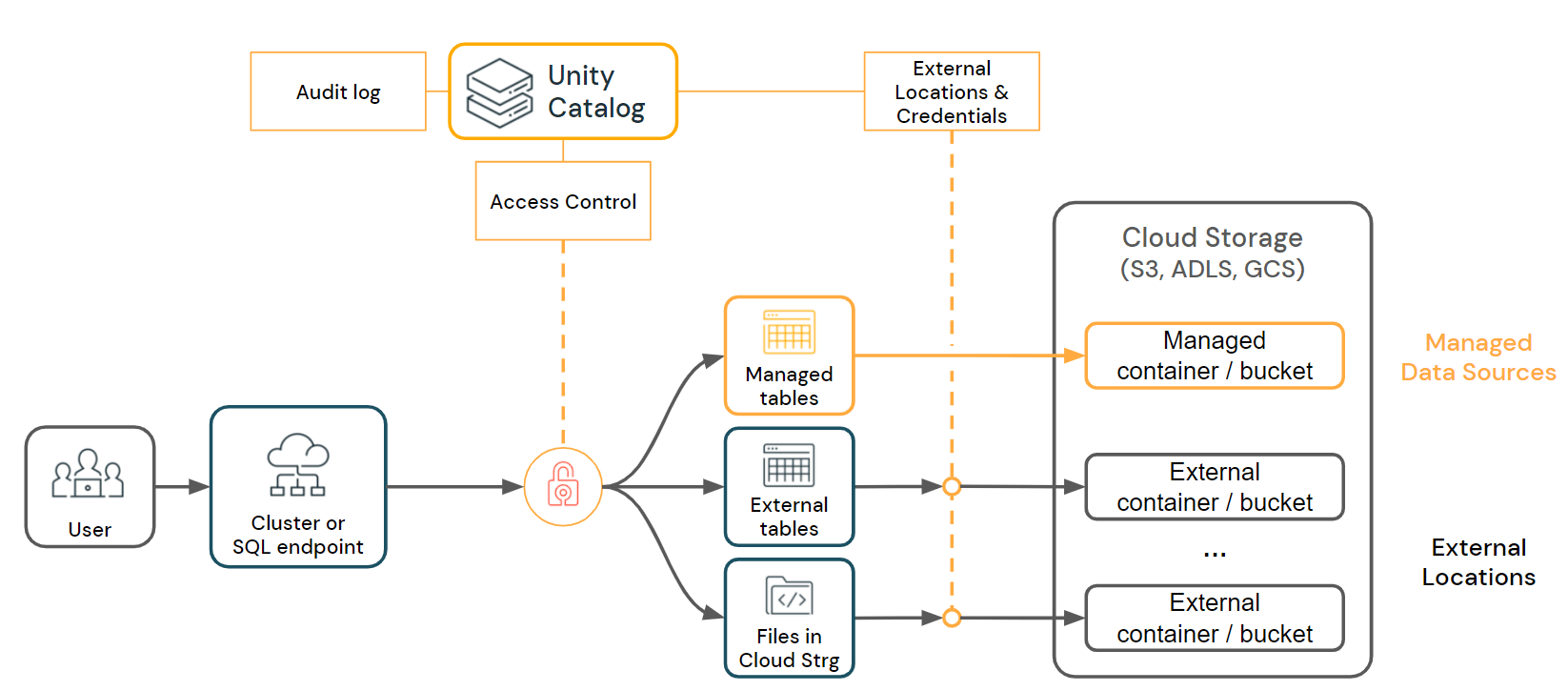
To understand Unity Catalog better, we need to examine its object model. This is the core of the technology.
Let's have a look at this object model in the image below:
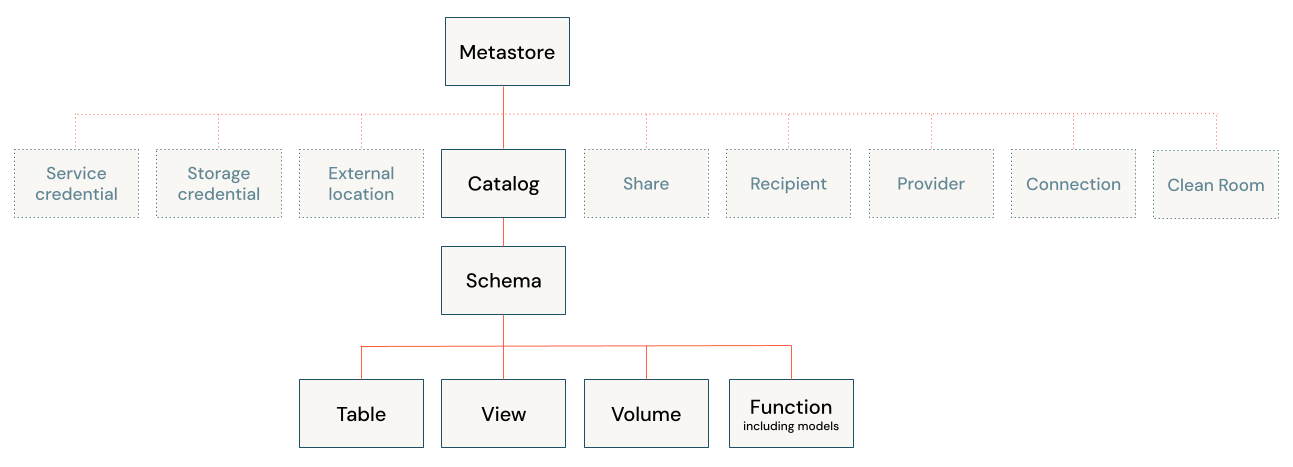
The object model follows a 3-level namespace: catalog.schema.object. Here’s a summary of its key components:
| Level | Component | Description |
|---|---|---|
| Metastore | Top-level container (1 per region/account) | |
| 1 | Catalog | Organizes schemas; similar to a traditional database |
| 2 | Schema | Holds tables, views, functions, etc. |
| 3 | Table | Structured data; can be managed or external with fine-grained access control |
| 3 | View | A logical layer on top of tables. It can also be used to create restricted data exposures. |
| 3 | Function | User-defined functions (UDF's) scoped to a schema |
| 3 | Volume | Managed storage for non-tabular data (files) |
| External Location | Links a storage path with a storage credential. This can be used for configuring managed storage locations or for the configuration of external tables/volumes | |
| Storage Credential | Wraps a long-term cloud credential for secure access |
With that foundation, let’s jump into the proof-of-concept.
Proof of Concept
The AS-IS Situation
Here's a diagram of the old architecture:

All resources from this architecture can be separated into two teams:
- 👷 Team A manages the data platform.
- 📊 Team B consumes the data for analytics.
Each team has three environments (Development, Quality Assurance and Production) with a separate Databricks workspace for each.
Key Characteristics
- 👷 Team A:
- All team members have full data access. Data is accessed using mount points backed by service principals.
- Standard tier workspaces to reduce costs.
- 📊 Team B:
- User-level data access using credential passthrough.
Each user has a personal compute (single-user access mode).
ACLs in the Data Lake are used to control access. - Premium tier is required for credential passthrough.
- User-level data access using credential passthrough.
Every workspace has its own hive_metastore.
Team A creates external tables that are manually replicated in Team B's workspaces.
This ensures both teams are always working with the same files and therefore the same data.
Notes
- Credential passthrough is deprecated starting with Databricks Runtime 15.0 and will be removed in future Databricks Runtime versions.
- Unity Catalog only works on Premium tier, which is the default for new implementations.
- Databricks has already deprecated the Standard tier for new customers on AWS and Google Cloud.
The TO-BE Situation
In the new setup, we kept the same workspaces but introduced Unity Catalog to break the barriers between the Hive metastores.
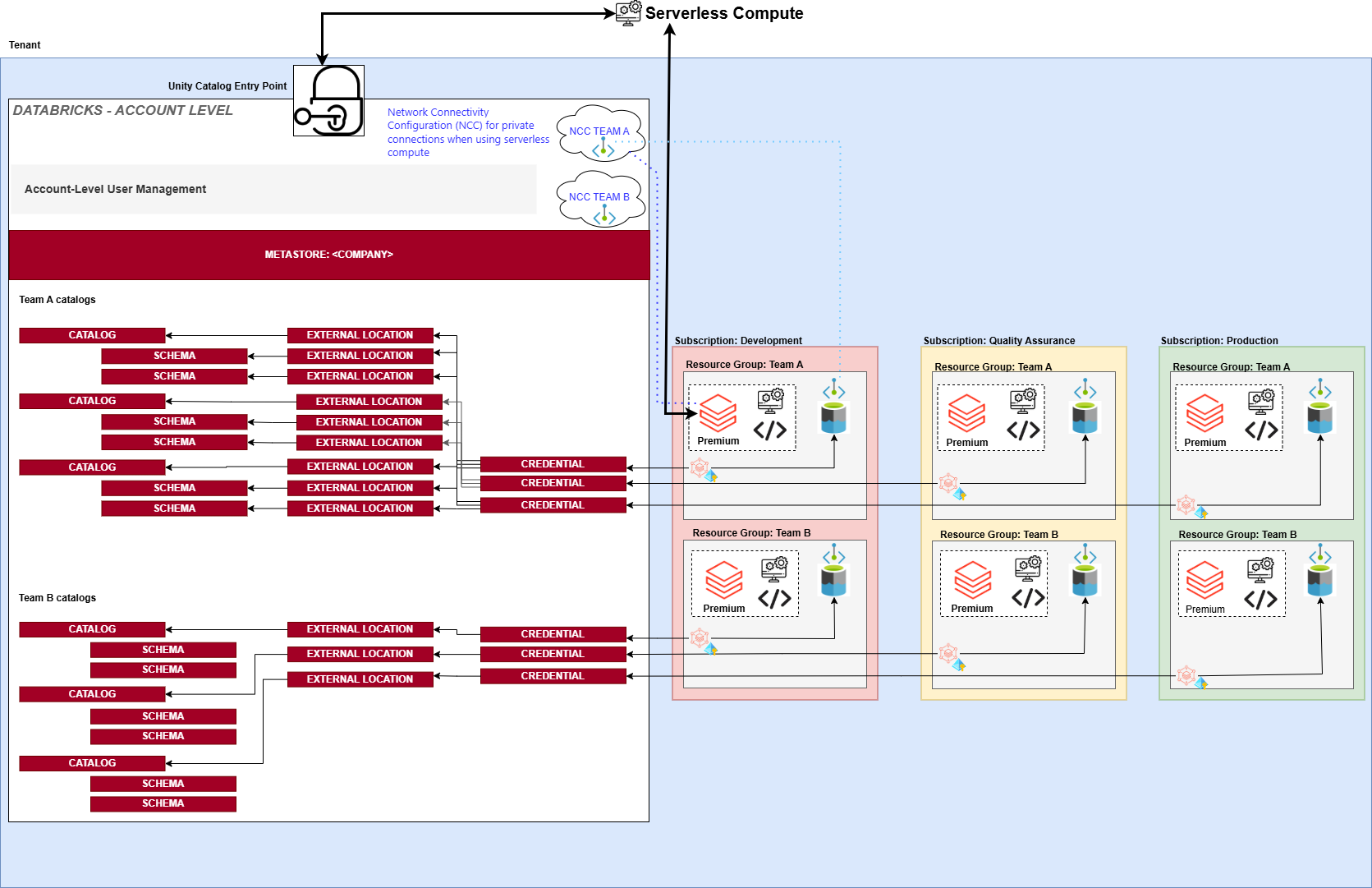
We created a single metastore for the company (metastores are limited to one per region/account).
Each combination of team and environment received its own catalog:
TEAM_A_DV,TEAM_A_QA,TEAM_A_PRTEAM_B_DV,TEAM_B_QA,TEAM_B_PR
This design provided a clear separation between the three environments in two ways:
- 💻 Code and compute: Handled by using multiple workspaces.
- 🧾 Data: Handled by using multiple catalogs.
Now let's have a look at some key steps we followed for setting up Unity Catalog.
- 🔌 Create Access Connectors: We created one per resource group (six total). These enable managed identity authentication.
- 🛡️ Configure Storage Credentials: Each access connector was linked to a storage credential in Unity Catalog.
- 📍 Create External Locations: The storage credentials were paired with a Data Lake path to define external locations.
- 🗃️ Create Catalogs and Schemas and specify Managed Storage Locations: These locations determine where data for managed tables and volumes will be stored. Managed Storage Locations can be specified at the metastore, catalog, or schema level.
- 🌐 Configure Network Connectivity Configurations (NCC's): Two NCC's were created for private endpoint connectivity between serverless compute and storage. We created one per team. NCC's are attached to workspaces.
As you can see, Databricks offers a lot of flexibility. Once you understand the key components, you can configure Unity Catalog to align with your architectural needs.
AS-IS vs TO-BE Comparison
Below is a breakdown of how Unity Catalog could improve the current way of working:
| AS-IS | TO-BE |
|---|---|
| 📎 Metadata is tied to workspaces and has to be (manually) duplicated. | 🗂️ Metadata is centralized. Easily share data across workspaces. Read-only access to production data from development is possible. |
| 🔗 Multiple external tables pointing to the same files. | 🤖 Both managed and external tables can easily be shared across workspaces. |
| 🔐 Access control via Data Lake ACLs is difficult to manage and restricted to table-level access. | 🧩 Access is directly managed in Unity Catalog using SQL or GUI. Support for row-level security, data masking, etc. Auditing can be done by reading system tables. |
| 📦 Mountpoints are used for accessing the storage accounts (Service principals or credential passthrough) |
🚫 No mountpoints anymore. Access Connectors are used to establish a connection with managed identities for secure access. |
| 👤 Personal compute with credential passthrough (legacy) needed for user-specific access. | 👥 No personal compute limitation anymore for user-specific access. From now on job clusters and SQL warehouses can be used to optimize cost and resource efficiency. |
| ⏳ Long cluster startup times for ad hoc testing due to personal compute. | ⚡Shared/serverless compute improves performance and reduces wait times. |
| 🧱 Legacy dependencies (DBFS, mountpoints, credential passthrough) block new feature adoption. | 🚀 Migration unlocks access to new features. One particularly useful example in this case was Lakehouse federation, which enables users to securely read and govern data across multiple external sources (ex. BigQuery) through a unified interface. |
Considerations for migrating to the TO-BE situation
For the proof-of-concept we moved one small flow.
Here's a summary of some key findings we encountered during the process:
- ✍️ Notebook references must be updated:
- Replace
hive_metastorein 3-level references with the appropriate catalog. - Specify the catalog when 2-level references were used. You can also specify a default catalog per workspace.
- Replace mountpoints with volumes
- Replace
- 💵 Upgrade to Premium tier required
- Increase in compute cost, but standard tier is being phased out anyway.
- 🐍📊 Only Python and SQL are supported for serverless
- ⚠️ R not supported in the
standard access mode(recommended compute option for most workloads)- Proceed with
dedicated access modewhich replaces the oldsingle-user access mode. This change introduced some compelling new capabilities. Compute withdedicated access modedoes not need to be assigned to a single user, it can also be assigned to a group. When it's assigned to a group, the user's permissions are automatically down-scoped to the group permissions.
- Proceed with
- 🔄 Credential passthrough can't be used on Unity Catalog enabled compute
- This means we could not create a hybrid situation where
hive_metastoreand Unity Catalog were used together for Team B.
- This means we could not create a hybrid situation where
Conclusion
Setting up Unity Catalog was straightforward as it is so well-documented. I genuinely enjoyed working on this project.
I’d even say it’s among the most elegant and powerful tools I’ve come across in the last five years.
That said, as with most migrations, the real challenge lies in untangling the existing setup and building a clear picture of all the running processes. Once that's in place, the hardest work is probably already behind you.
A migration will take time, but this time is well spent. It not only enables a more future-proof environment but also strengthens the foundation of your data platform in terms of governance, security, and data ownership. This paves the way for a more manageable architecture, improved data quality, and ultimately, better business decision-making.